As many readers of my webpages might
remember there was a nice "blogwar" last year regarding the quality of
the NMRShiftDB-data initiated by a quality-check according to the usual
CSEARCH-criteria. I dont want to discuss if 6,200 ppm assignment errors
found and corrected within 2 hours are small or large - I simply want
to know after 1 year, which mechanism have been built into NMRShiftDB
in order to avoid such misassignments.
Therefore
my question:
Which mechanism have
been implemented into NMRShiftDB during the last 12 months in order to
avoid obvious assignment errors ?
NMRShiftDB is an Open Source and Open
Access NMR-database system with 1,484 registered user (as per March
26th, 2008) - therefore every contribution to this system influences
future assignments very effectively. Assume the situation, you are
working on a specific class of compounds and rely your C-NMR
assignments on a wrong reference dataset from NMRShiftDB. The
consequence is again a wrong assignment; now this wrong assignment goes
back into NMRShiftDB, because you want to contribute to this OPEN
system. What happens: When doing the next assignment for a similar
partial structure, this assignment is now based on better statistical
parameters ! A database - as a collection of (hopefully) facts - has a
high impact on upcoming science - therefore any database supplier has a
high degree of responsibility for the content (s)he provides. Data
curation is therefore of extremely high value, but a prerequisite of
data curation is error-detection - therefore I
repeat my question: Which mechanism have been implemented into
NMRShiftDB during the last 12 months in order to avoid obvious
assignment errors ? Other systems like "chemspider" have put a lot of effort into
this topic and have discussed their efforts very frequently on their weblogs.
When
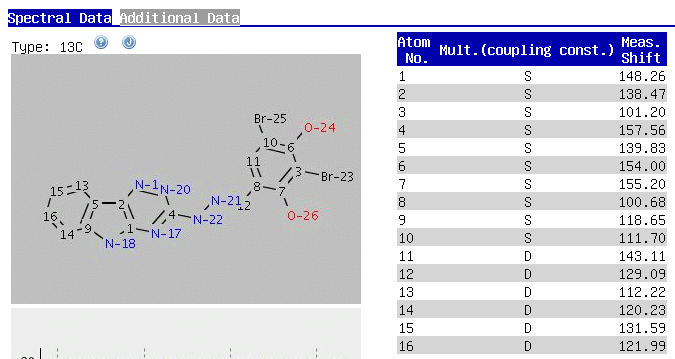
going to NMRShiftDB there is a column 'Latest
Additions' on their homepage. The newest entry from March 21st,
2008 is shown in the slide below (screendump from March 26th,2008). The
CAS-Registry number of this compound is 324029-99-4; there is no
literature citation given for this compound in the CAS-Registry-File -
therefore this seems to be an unpublished result contributed by J.
Beutler according to the structural and spectral identifier
(nmrshiftdb.cubic.uni-koeln.de_jbeutler_2008-03-21_03:48:07_0415)
Translating
this entry into a CSEARCH-type display gives
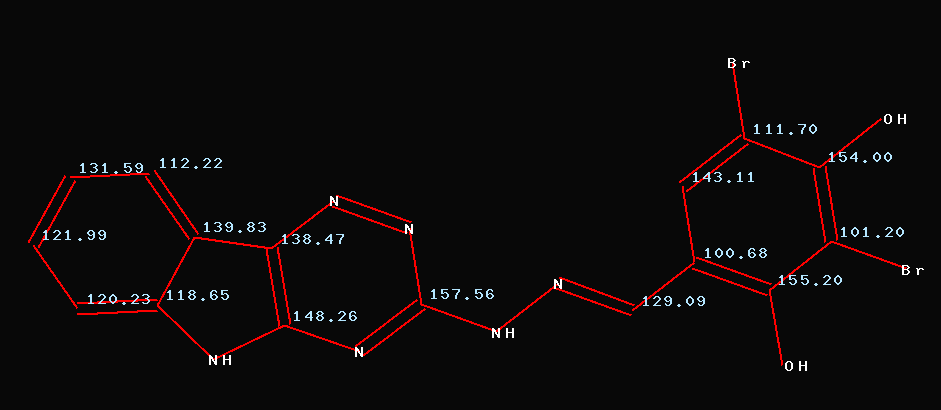
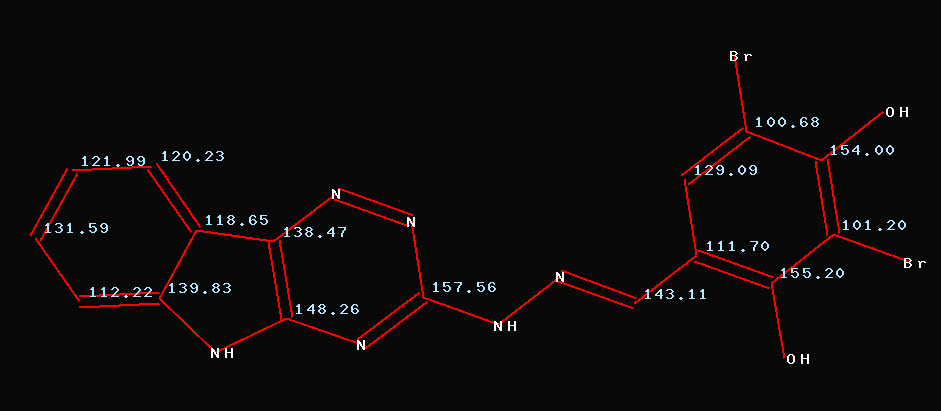
Comparing
this entry against the predicted values using CSEARCH-NN-Technology
gives an average deviation of 7.7ppm per carbon. Reassigning the
following pairs: 15/16; 13/14; 5/9; 11/12 and 8/10 reduces the average
deviation to 1.8ppm per carbon. This assignment is shown in the next
slide. Please
note that the average deviation for the pair C5/9 is more than 20ppm
per carbon!
Please keep in
mind: The original assignment has been done using HH-COSY, HMQC and
HMBC, the proposed assignment is based only on shift-arguments; I have
never seen any 2D-NMR of this compound !
I
would highly appreciate to see the original 2D-NMRs somewhere on the
net - let me know, when my assignment proposal is wrong ! Your comments
are highly appreciated on my weblog.
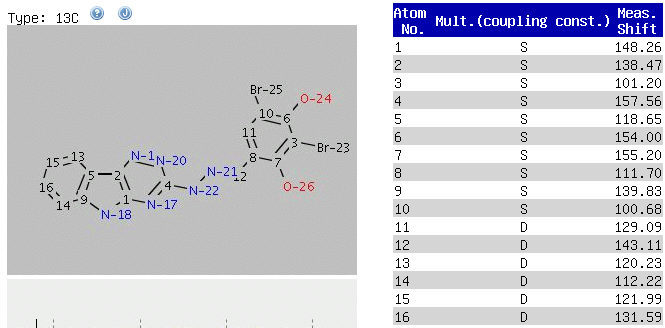
Since
March 29th, 2008 the corrected dataset is available on NMRShiftDB. All
corrections proposed by me have been performed on this dataset. Please
keep in mind, the original assignment has been done by extensive
application of 2D-NMR (HH-COSY,HMQC and HMBC) - I have never seen them,
my corrections are solely based on one simple prediction using CSEARCH.
According to the access-protocols of
my webserver, I am quite sure that my proposed assignment has been
checked using another professional program. I am quite happy that all
my proposals have been verified by this independent test.
What are the facts:
- An assignment of a C16-compound based on extensive use of 2D-NMR
produced 10 assigment errors
- Two independent checks by two professional prediction programs
lead to the same corrections, solely based on their prediction
capabilities for chemical shift values.
- NMRShiftDB is Open, both other programs are not open, but without
their help, the 10 misassignments would influence further assignment
and make them statistically spoken, more confident.
- The argument - "This
error could be corrected, because the data are open" - is
definitely wrong ! Within a more professional prediction system such an
entry would never leave the 'purgatory database' - and therefore never
'dilute' the 'production database' of well-verified datasets.
Page written
on: March 26th, 2008
Last modification on: March 29th, 2008
Page written by: Wolfgang.Robien(at)univie.ac.at